Checking Indexation of Large Enterprise Websites
Have you ever wondered if all your site’s pages were indexed and cached by Google? *Really* indexed? Turns out there are many SEOs asking this question, but few simple ways to be sure. Yes, you could manually check by copy pasting a page snippet into Google, but on an Enterprise site you’d be retired before finishing. There are tools that claim to do this, but some work and some do not. Let’s start with “Why” before we get into “How”.
Doesn’t Google Know My Site Better than I do?
There are various reasons why pages may not be in Google’s index. Large sites typically contain multiple business units, with differing goals and supporting dev teams. It’s easy for a directory to be no-indexed via exclusion in the robots.txt file, or new sandboxed pages may have no-index tags that are accidentally not removed once the page is transferred to the production environment. SEOs are typically chasing mountains of optimization projects and can easily miss sections of site content that are not indexed. On Google’s side, if a page is not linked to by other indexed pages, it can be considered an “orphan” and not crawled. If it is shallow content, it may be considered duplicate content, meaning it is crawled and indexed but not cached and therefore not eligible to show for searches.
“Deep Indexation” Sounds Painful. What is it?
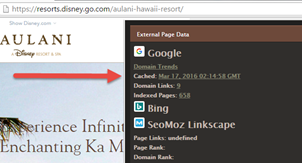
Google’s index is constantly evolving, and SEO professionals’ understanding of how Google’s algorithm and Googlebot indexation methods work is constantly evolving as well. It turns out that the question of if a page is Cached/Indexed is not just a “Yes”/”No” answer. Pages can be “Indexed” yet only show for very specific, low-traffic queries (therefore worthless for SEO). There is more to the process than just using the “info: search” operator to determine 100% if a given page is indexed by Google. Often large sites contain large numbers of “indexed” pages that will not actually show for ordinary searches that do not, say, contain the exact page URL. The process of determining the composition of these pages is explained in depth by the URL Profiler folks.
There are several ways to check if one’s site is Indexed.
- Google a snippet of site content. If done correctly (especially using non-branded content), this is one of the most reliable methods, but also the slowest.
- Use the “site:” search modifier with the page URL.
- Use a tool such as a Chrome plugin like SEO Site Tools. Slightly faster, but also less reliable.
- Compare all pages that have received an organic visit to the sitemap. If all sitemap pages have received at least one Organic click, you’re golden.
- Use a tool such as Screaming Frog or DeepCrawl to check which pages are indexable. This is the easiest way to quickly scan a large website, but it only checks if pages are excluded due to robots file or page-level No-index tags, not if the page is actually indexed. If Google decides not to index a page because, for example, it considers it duplicate content, you won’t know.
-
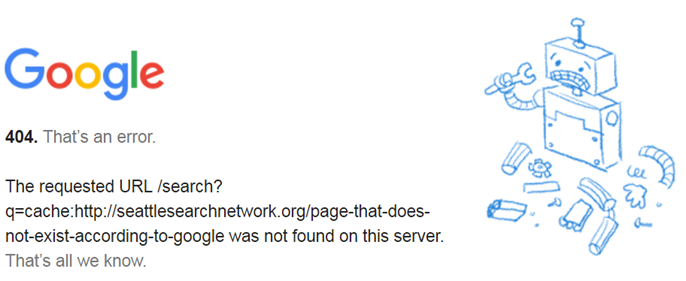
Check the webcache: version of every important page on the site for existence. If no 404 – Bingo! The page must have a cached copy. For example, the below webcached URL shows a cached page, no 404 http://webcache.googleusercontent.com/search?q=cache:http://resorts.disney.go.com/aulani-hawaii-resort/dining/ therefore the page http://resorts.disney.go.com/aulani-hawaii-resort/dining/ must exist in Google’s cache. How best to do this?
- Use a Google Sheets doc to check 30-100 URLs at a time. Scripts allow automatic running, but after 30-100 URLs the doc will stop working. Proxies would likely help. Be prepared for this method to work only intermittently.
- Use a tool such as Screaming Frog to check 30-100 URLs at a time. Again, seems easy but Google will ban access after a small # of URLs.
- Use a Google Sheets doc to check 30-100 URLs at a time. Scripts allow automatic running, but after 30-100 URLs the doc will stop working. Proxies would likely help. Be prepared for this method to work only intermittently.
- Use a purpose-built tool such as URL Profiler to check website indexation. 5-10 proxies should allow checking 10-50k URLs per night.

The remainder of this post will assume you’re using the URL Profiler tool.
The Process
Step 1: Map Your SIte
It’s imperative to have an accurate, up-to-date XML sitemap to be checked. If your sitemap needs polishing, start there first. Also critical that sitemap URLs allign to canonical tags. If a valuable page’s tag points elsewhere, say goodbye to it’s ability to rank.
Step 2: Getcher Proxy on
For checking over 1000 URLs, Proxy IPs are a must. URL Profiler has a guide on how to use them. Squid and “Trusted” Proxies are well-known but best luck was had with VPN Proxies. Be sure to authorize them (and allow to propagate) before using.
The reason for using proxies is that Google does not approve of programs scraping their search results, or even large amounts of manual searches from an individual IP address. After a random period of many Google searches or scrapes of Google results, you will be required to fill out CAPTCHA boxes. The same is true of proxies, if you hammer them too hard they will just get blocked. In most cases, just like with a personal IP address, if you just wait for a few hours then the block will disappear. If this doesn’t happen, you can speak to the proxy provider and ask them to reset the proxies.
When URL Profiler handles proxy requests, it looks at how many proxies you have and tries to spread the requests out over time to make them look less unnatural. The more proxies you have, the easier this is, so in general you will get less ‘Connection Failed’ errors with more proxies. If you are processing in one go, 10 proxies is a normally a good number for 500-1000 URLs at once. 20 should work for up to 10k. But if you keep re-running them, Google may notice and block them.
The URL Profiler folks built a handy little standalone proxy checker tool. Run the .exe file then import proxies down on the left, and then hit run. This will tell if proxies are “Google Safe”. Apparently they are planning to integrate it into their main tool sometime. Scrapebox has similar functionality.
Step 3: Profile Some URLs
Read Patrick Hathaway of UP’s excellent How to Guide. Patrick goes into much more detail but the key point is that while pages may show up as “Cached”, they may be in Google’s “Deep Index”, which basically means Google’s aware of them and will show them for an info: search or exact-page-text search, but NOT for any valuable searches an ordinary consumer might use. Moz’s Rand Fishkin has more thoughts on the many “Levels of Indexation“.

Import the site’s sitemap and let ‘er rip, preferably overnight.
Sometimes the tool will show pages as un-indexed but a manual check (method #1) will show that they are indeed indexed. Double-checking and manual-validation of the pages indicated as non-indexed is essential, unfortunately. But the tools make it much easier to shrink a large site down to a short list of potentially problematic URLs to check.
Eventually, you should end up with something like this:
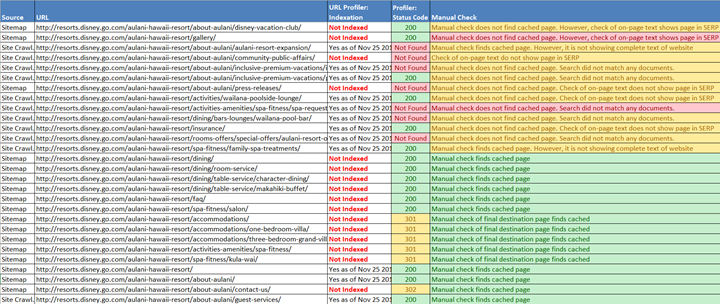
Then it’s time for the fun part! Figuring out WHY pages are not indexed can be a real challenge sometimes. Luckily, others have already felt your pain:
- https://moz.com/ugc/8-reasons-why-your-site-might-not-get-indexed
- https://blog.kissmetrics.com/get-google-to-index/
- http://blog.woorank.com/2013/05/11-steps-to-get-your-site-indexed-on-google/
- https://support.google.com/webmasters/answer/6259634
- Super-Special Bonus Hint: Many crawlers such as Screaming Frog have the capability to crawl a site as Googlebot, making it easy to find hidden problems only affecting Google.
Your goal:
Case Studies FTW: Google Gets All Up in The Mouse’s Business
Even with a purpose-built tool, checking the indexation of enterprise-size sites, let alone a multitude of them, is not for the weak of heart or easily-dissuaded SEOs. As part of your humble correspondent’s desire to discern the truth about Indexation-checking, the most promising method (URL Profiler) was used, along with 30+ proxy IDs, to check 8,300 URLs across 12 Disney Parks websites.
Conclusions for the Mouse
Disney Parks’ sites appear to be in good shape. The vast majority of sitemapped pages on all 12 sites were, indeed, indexed by Google. But most sites had some or many un-indexed pages, and problems with duplicate content and architectural issues were uncovered. At the end of the process, 607 important but un-cached pages were uncovered, plus a serious problem with the homepage of a high-value site.

Problems:
- All sites with different language versions had 20+ invisible pages, likely due to duplicate content issues. Solution was comprehensive implementation of HREFLANG tags. The biggest problem was different country sites with the same language (Belgian Flemish vs Nederland’s Dutch)
- Many Maps pages did not show up. This was unsurprising, as in their current form they are likely not worth promoting, but worth re-visiting if the content can be improved.
- Many Disneyworld.com list pages do not show up well. Instead, the almost identical content on Attractions pages showed. The easiest fix was canonical tags, to strengthen the top (Attractions) content.
- HKDL (hongkongdisneyland.com) homepage. This was a major problem uncovered as part of this process. The site’s homepage was redirecting Googlebot to a NOINDEX page. SEO team FTW!
Details
- disneyworld.disney.go.com: 243 non-indexed pages out of 3846. Majority (150) are Spanish language (/es-us/).
- disneyland.disney.go.com: All 907 cached.
-
www.disneylandparis.fr: 25 non-indexed pages(but duplicate pages are indexed) out of 566, using google.fr.
- www.disneylandparis.co.uk: 26 non-indexed (but many are /maps/ pages or have duplicate pages indexed) out of 549, using google.co.uk.
- www.disneylandparis.de: 55 (but many are /maps/ pages or have duplicate pages indexed) out of 520, using google.de.
- www.disneylandparis.nl: 17 (due to conflicts with dlp.be/nl/) out of 359 using google.nl.
- www.disneylandparis.be/nl/: 192 (due to conflicts with dlp.nl/) out of 570
- www.disneylandparis.be/fr/: 155 (due to conflicts with dlp.fr/) out of 156
- www.hongkongdisneyland.com: The homepage was not indexed, out of 334, using google.com.hk.
- resorts.disney.go.com/aulani-hawaii-resort: All 120 cached.
- www.adventuresbydisney.com: All 198 cached.
- disneyinstitute.com: All 496 cached.
Note that all data points in this article are publically available.
Further Resources
- http://urlprofiler.com/blog/google-index-checker/
- http://urlprofiler.com/blog/google-indexation-checker-tutorial/
- https://www.deepcrawl.com/case-studies/elephate-fixing-deep-indexation-issues/
- https://www.deepcrawl.com/knowledge/best-practice/how-to-measure-indexed-pages-more-accurately/
- http://www.blindfiveyearold.com/optimize-your-sitemap-index